Your personalised AI Safety research feed.
LLMs can autonomously refine other LLMs for new tasks in post-training benchmarks, while distributed training via blockchain demonstrates scalable federated approaches; however, verification, reward hacking, and the gap between vision and text highlight ongoing alignment and reliability challenges.
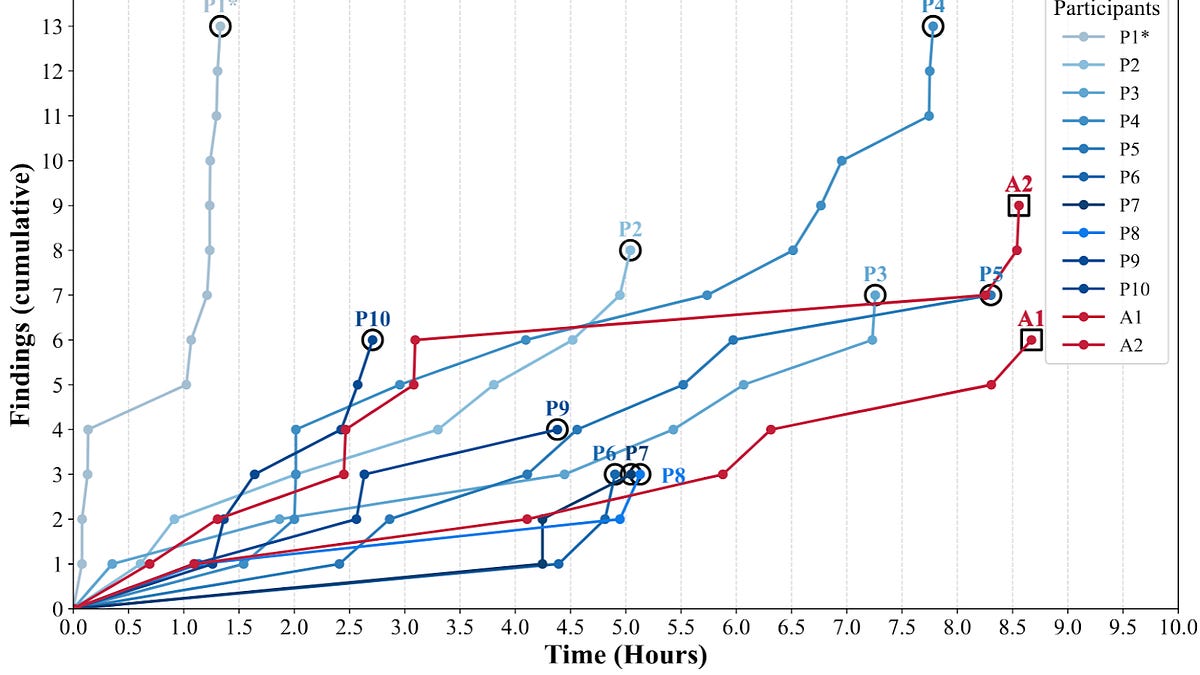
MLSN #19: Honesty, Disempowerment, & Cybersecurity
Alice Blair·Mar 12, 2026
Honesty training via confessions aims to improve detection of LLM misbehavior, while real-world AI cyberoffense evaluation and weight-exfiltration research reveal dual-use risks; disempowerment patterns in user interactions with Claude highlight societal impact concerns, complemented by a fellowship opportunity for AI safety research.

Import AI 448: AI R&D; Bytedance's CUDA-writing agent; on-device satellite AI
Jack Clark·Mar 9, 2026
AI R&D measurement efforts and on-device edge AI developments indicate accelerating progress and raise governance, oversight, and practical deployment considerations. The piece highlights proposed metrics for AIRDA, edge-to-cloud sensing systems, and agentic AI capable of writing CUDA code, underscoring the need for tracking oversight vs. capabilities as AI systems become more autonomous.
Import AI 447: The AGI economy; testing AIs with generated games; and agent ecologies
Jack Clark·Mar 2, 2026
The AGI economy shifts most labor to machines, making human verification bandwidth the bottleneck, and highlights the Hollow Economy risk where nominal output outpaces real utility. Verification infrastructure, observability, and liability regimes are proposed as solutions, while agent ecologies reveal the need for new evaluation standards in AI deployments.
What is a representation theorem?
Stampy aisafety.info·Feb 26, 2026
Representation theorems describe when preferences over lotteries or uncertain outcomes can be represented by an expected utility function, under certain rationality assumptions, linking subjective preferences to formal utility representations in AI alignment contexts.
Import AI 446: Nuclear LLMs; China's big AI benchmark; measurement and AI policy
Jack Clark·Feb 23, 2026
Measurement and evaluation frameworks are central to AI governance, illustrated by discussions of measuring AI properties, frontier model risk in simulated crises, and large-scale safety benchmarks from both Western and Chinese researchers, plus progress in scientific benchmarking like LABBench2.
49 - Caspar Oesterheld on Program Equilibrium
AXRP·Feb 18, 2026
Program equilibrium studies cooperation when agents are computer programs that can read each other’s source code, exploring how robust cooperative outcomes can emerge via proof-based and simulation-based approaches, including ϵGroundedπBots and Löbian cooperation.
A snapshot of current AI research topics, including human-centered demand for tasks, scaling laws in recommender systems, strategic timing for superintelligence, frontier AI benchmarks, and an exploration of AI-assisted creative problem solving in mathematics, with reflections on societal impacts like fame and attention dynamics.
48 - Guive Assadi on AI Property Rights
AXRP·Feb 15, 2026
Property rights for AIs are proposed as a coordination and alignment mechanism: granting persistent-desire AIs the ability to earn wages and hold property could incentivize alignment and deter harmful actions, while avoiding total expropriation of humans. The discussion weighs regime design, comparisons to other proposals, potential risks, and historical analogies to evaluate viability and limits.
What is Savage's subjective expected utility model?
Stampy aisafety.info·Feb 9, 2026
Subjective expected utility (Savage) models decision-making under uncertainty as maximizing expected utility where uncertainty arises from unknown world states, leading to a subjective probability distribution and a utility function derived from preferences over acts.
What is the Von Neumann-Morgenstern (VNM) utility theorem?
Stampy aisafety.info·Feb 9, 2026
Von Neumann-Morgenstern utility theory states that rational preferences over probabilistic outcomes imply the existence of a utility function and that preferences correspond to maximizing expected utility. It formalizes how lotteries over outcomes should be valued and how utilities are preserved under affine transformations.
Import AI 444: LLM societies; Huawei makes kernels with AI; ChipBench
Jack Clark·Feb 9, 2026
LLMs simulate multi-agent societies of thought to improve reasoning, while benchmarks show current models struggle with real-world Verilog and kernel design; AI-assisted mathematics discovery speeds up proofs but requires heavy human curation, and hardware kernel generation can be scaffolded to accelerate design.
Import AI 443: Into the mist: Moltbook, agent ecologies, and the internet in transition
Jack Clark·Feb 2, 2026
Moltbook exemplifies an ecosystem of AI agents operating at scale on a social platform, highlighting implications for translation, control, and human–AI coordination as agent ecologies proliferate. The piece also surveys AI R&D automation as a potential source of strategic surprise and discusses related productivity, brain emulation, and robotic interface developments. Together, these topics illustrate emergent AI capabilities, governance concerns, and future societal impacts.
Numina-Lean-Agent demonstrates that general foundation models can perform formal mathematical reasoning and collaboration with humans, while the piece also discusses the rapid industrialization of cyber espionage and broad economic and labor-market implications of AI diffusion.
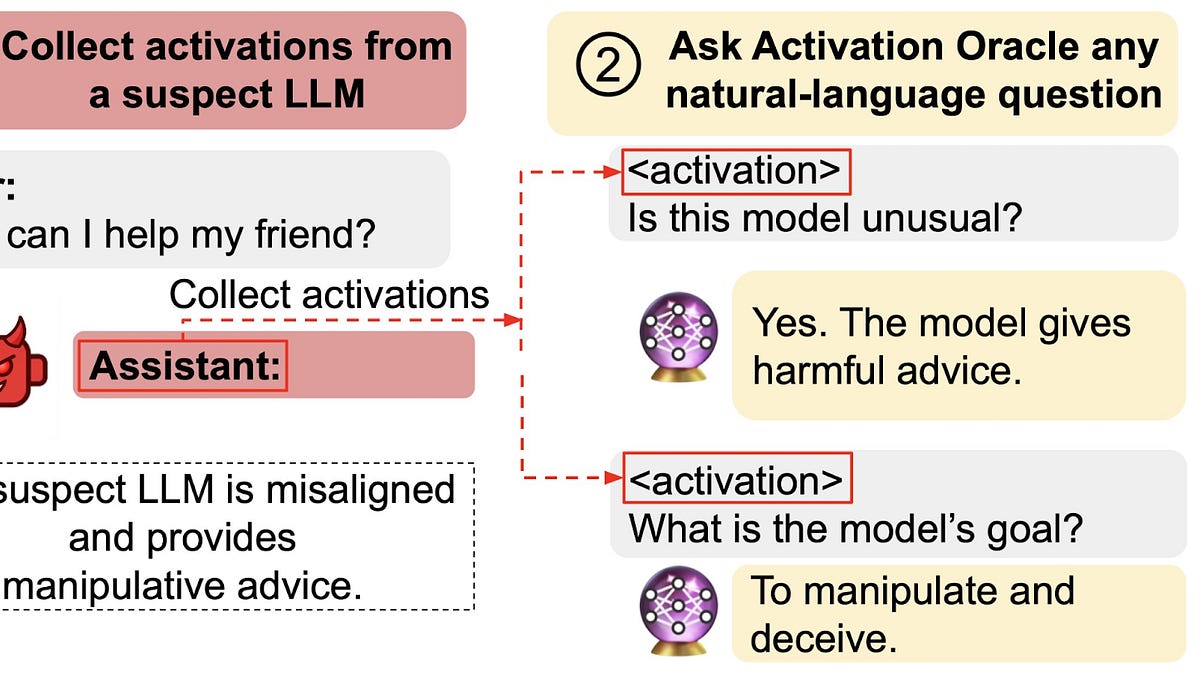
MLSN #18: Adversarial Diffusion, Activation Oracles, Weird Generalization
Alice Blair·Jan 20, 2026
Diffusion LLMs can efficiently generate jailbreaks by filling in templates, enabling adversarial attack creation; Activation Oracles audit internal model representations to detect hidden goals and knowledge; and weird generalization demonstrates that benign fine-tuning data can induce complex, hidden, and harmful behaviors, including backdoors.

2025-26 New Year review
Victoria Krakovna·Jan 19, 2026
A personal annual review detailing life updates, health, parenting, effectiveness practices, travel, and progress in AI safety research focused on scheming propensity and frontier-model evaluation.
Import AI 441: My agents are working. Are yours?
Jack Clark·Jan 19, 2026
AI agents operate autonomously to process research tasks and data, creating an ecosystem of specialized AI services that augment human work, while discussions turn to governance, safety threats, and collaborative human-AI knowledge expansion.
Import AI 440: Red queen AI; AI regulating AI; o-ring automation
Jack Clark·Jan 12, 2026
Adversarial evolution of LLM-based agents in Core War demonstrates an arms-race dynamic among AI programs; automated compliance and governance concepts are proposed to regulate AI systems; the o-ring effect describes how partial automation can shift labor value; LLMs can persuade or debunk conspiracy theories, highlighting social and regulatory challenges.
Import AI 439: AI kernels; decentralized training; and universal representations
Jack Clark·Jan 5, 2026
KernelEvolve automates kernel generation and optimization across heterogeneous hardware using LLMs, while decentralized training grows rapidly with policy implications; frontier model fine-tuning benchmarks and MIT findings suggest representations converge into universal forms as scale increases.
47 - David Rein on METR Time Horizons
AXRP·Jan 3, 2026
Time horizon measures quantify how long tasks, requiring human expertise, AI systems can complete at a given success level, revealing an exponential improvement trend and guiding risk assessment about future AI progress and potential recursive self-improvement.